Recently me and Marq have been exploring fast and smooth sprite graphics on the 48k Speccy. It's a much discussed topic, yet remains fascinating. Moving graphics can be done in so many ways, and it is not always obvious what to aim for. Games use various tricks to ease the load, and the tricks in turn depend much on what the game is about.
It's still wise to try to build a generally useful sprite engine, before optimizing for different contexts. So far we have managed eight 16x16 masked, freely positioned, flicker-free, smoothly moving sprites, as shown in the above video. (Check also this Youtube video)
This first part opens up the basics of the topic. If I get to write an improved version, there will be a Part II.
A 16 x 16 sprite is a common starting point. Any problems related to it can be applied to larger sprites. The above image shows a 32-byte definition of such a sprite. From left to right, top to bottom, the bits would translate to following decimal bytes:
7,224,24,24,32,4,78,2,95,2,159,1,142,1,128,1,128,1,128,1,128,25,64,58,64,50,32,4,24,24,7,224
This corresponds to the way the Spectrum stores pixels, one bit per pixel, a byte for eight pixels. The memory-mapped screen is found from the address 16384 onwards. A POKE 16384,255 in BASIC will quickly show this.
Screen BASICs
The ZX Spectrum display is notoriously a bit disordered, so one of the first issues is to resolve the drawing order. At first glance, it would seem to be enough to increment the drawing address with one byte for each column and 256 bytes for each row. Then, a routine like the one below would render our sprite on screen:
5 REM DOES NOT WORK
10 LET ADD=17184
20 FOR B=0 TO 15
30 READ L
40 READ R
50 POKE ADD,L
60 POKE ADD+1,R
70 LET ADD=ADD+256
80 NEXT B
100 DATA 7,224,24,24,32,4,78,2
110 DATA 95,2,159,1,142,1,128,1
120 DATA 128,1,128,1,128,25,64,58
100 DATA 64,50,32,4,24,24,7,224
If only:
 |
| Uh oh. |
But we're on right track somehow. At least something is happening on screen. As it stands, the address logic changes after every eighth pixel row, as shown in the diagram below. The picture shows in detail the structure of the top left corner of the Spectrum screen, where I tried to draw my sprite. Inside the character row, each pixel row is nicely 256 bytes apart, but the first addresses of each character row are 32 bytes apart.

Furthermore, the screen is divided into three 64-pixel high "slices", each having a start address 2048 bytes apart. Zooming out, the leftmost screen addresses for each character row (every eighth pixel row) are laid out as follows:

This ordering is quite good for drawing 8x8 characters aligned to the character rows. One might even call the Spectrum screen layout a pseudo-character display. But a generic sprite routine has to negotiate the 8-line "boundaries" as well as the two "slice" boundaries.
The BASIC program below identifies the slice block and character rows for a given vertical pixel coordinate, and draws the "sprite" accordingly.
10 FOR S=0 TO 15
20 LET Y=11+S
30 LET BLOCK=INT (Y/64)
40 LET CROW=INT (Y/8)
50 LET YR=Y-(CROW*8)
60 LET CROW=CROW-(BLOCK*8)
70 LET ADD=16384+BLOCK*2048+CROW*32+YR*256
80 READ L: READ R
90 POKE ADD,L: POKE ADD+1,R
100 NEXT S
110 DATA 7,224,24,24,32,4,78,2
120 DATA 95,2,159,1,142,1,128,1
130 DATA 128,1,128,1,128,25,64,58
140 DATA 64,50,32,4,24,24,7,224
 |
| OK, indeed |
The object described here hardly deserves the name "sprite". BASIC is simply too slow, and there's lot more to do than just laying the bits on screen. Proper sprite routines can only really be done in machine code.
Even then, it's possible to improve the above listing, by calculating the addresses beforehand into a table. It would be a bit silly to calculate the address for each sprite row.
10 REM PREPARE A TABLE
20 DIM A(176)
30 FOR Y=0 TO 175
40 LET BLOCK=INT (Y/64)
50 LET CROW=INT (Y/8)
60 LET YR=Y-(CROW*8)
70 LET CROW=CROW-(BLOCK*8)
80 LET ADD=16384+BLOCK*2048+CROW*32+YR*256
90 LET A(Y+1)=ADD
100 NEXT Y
110 REM DRAW THE SPRITE
120 RESTORE 180
130 FOR I=0 TO 15
140 READ L:READ R
150 POKE A(11+N),L: POKE A(11+N)+1,R
160 NEXT I
170 DATA 7,224,24,24,32,4,78,2
180 DATA 95,2,159,1,142,1,128,1
190 DATA 128,1,128,1,128,25,64,58
200 DATA 64,50,32,4,24,24,7,224
At least in this respect, writing sprite routines in assembler is not that different. It's about finding ways to offload the burden from the drawing parts. This is why many fast routines use a buffered drawing of some sort.
Sprite shifting
The BASIC listings simplified many things. Much has been said about the vertical coordinates. How about the horizontal? Fiddling with the BASIC listings above would show that adding one to the sprite position address moves the sprite one character column to the right. This at least is straightforward, but it is not smooth. There are ways to recalculate the sprite graphics on the fly, but pre-shifted sprites are easier and faster.
| A 16x16 sprite GFX and its' mask, with room for shifting. |
Shifted 16x16 sprites are in reality 24x16 sprites, and each graphic needs 8 shifted variants. This way they can be aligned horizontally with the character columns. The downside is that it takes more memory.
All the sprite variants also need a mask, which is an inversion of the area that will be cleared before drawing the proper sprite. This way the sprites can be drawn over a background without showing any of the pixel background through the sprite, or producing other ill effects. Many games get away without using masks or backgrounds, and can even look better for it (think Dan Dare), but such an approach is hardly generic.
The machine code routines discussed below use shifted sprites.
Sprites in z80 machine code
Smooth sprite movement has to be tied to the screen update cycle, which is refreshed 50/60 times a second. In machine code, the HALT instruction tells the processor to wait until the refreshing beam has returned to the top of the screen.
After this, the beam travels right, returns to the left side of the screen and travels down, refreshing the screen during the process. To avoid flickering and glitches, changes to the screen should be done before the beam hits the drawing area.
So, a conventional sprite-drawing program might follow this order:

The z80 running at 3.5mhz can do quite a bit before the beam is arrives at the pixel area. (Or "the display file" as it is called in the official Spectrum manuals.)
Of course, even when the beam is in the pixel area, things can be drawn below the current beam position, and the results will still be smooth. Many scene demo effects take advantage of "racing the beam" in this way. Even a sprite routine may benefit from such a scheme, but for a generic routine the drawing is safest to do before the beam arrives at the pixel area.

The sprite program shown in the video follows the order below. The border colours are not just for fun, but for showing what actions are being taken at that scanline position. The routine draws the sprites into a hidden buffer screen, and uses a fast copy routine to do bring them on the visible screen. An address table holds the position information for the fast copy routine.
BEFORE THE LOOP:
- Copy the entire background image to the entire buffer
- Draw sprites to buffer and create a new address table for them
- Wait Vertical Blank (=HALT instruction)
- RED: Copy bytes to screen from buffer, using the sprite address table
- BLUE: Copy background to sprite positions at the buffer, using the sprite address table
- YELLOW:Change sprite coordinates
- BLUE: Store the address table
- YELLOW:Draw sprites to buffer and create a new address table for them
- BLACK: Wait until the beam is outside the pixel area (estimated)
- RED: Copy background to sprite positions on the screen, using the stored address table
Note that here the sprites are drawn well before the beam arrives at the pixel area. The fast copy routine could even move 12 sprites to the screen. Yet drawing more than 8 sprites altogether (buffer, clearing) is not yet possible. It's easy to see though, that there are ways to reduce the load, especially the needless duplicating of the address table.
Buffered drawing
In this sprite routine, there are three "screens": The real display screen, a source background image and the drawing buffer. In addition, the sprite graphics need to be stored somewhere.
The diagram below shows the Phase 6 in the above list. (The second "yellow" portion.) Here we draw the sprite to the invisible buffer screen and store its screen position as an address into the sprite address table for later copying.
The actions required for drawing a single byte are highlighted. The diagram only shows the part relevant for the sprite, which in this case is drawn to the top left corner of the buffer, waiting to be moved on the same relative screen position. The mask and graphics are interleaved for purposes which is explained later.
 |
| Phase 6: The diagram illustrates how the sprite is drawn into the buffer screen. |
Each time the sprites are drawn to the buffer, an address table is also renewed. The address table is at the heart of the fast drawing routine (phase 2). One sprite has 16 rows, so drawing a sprite to the buffer also writes 16 addresses to the table. The address table points to the locations in the drawing buffer, from which the sprites are copied after the HALT:
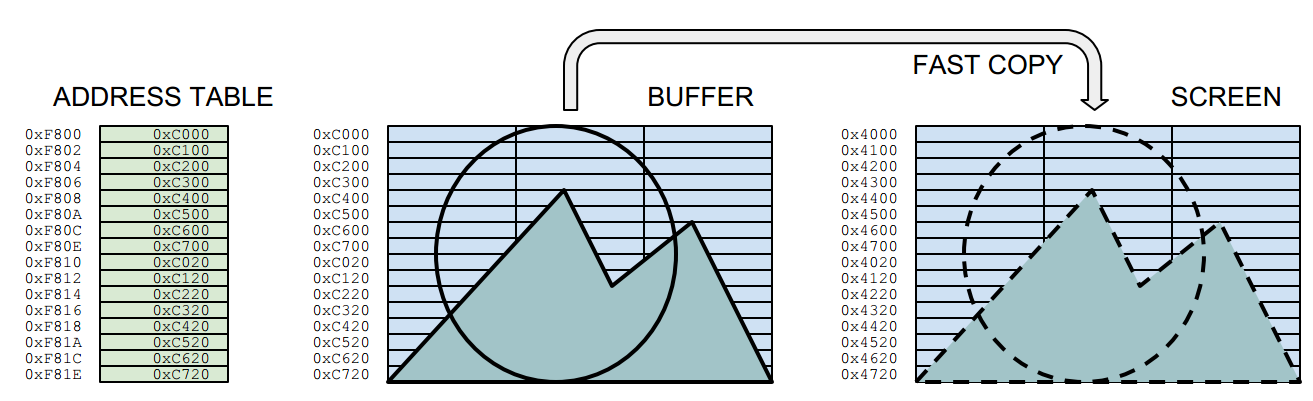 |
| Phase 2. Fast copy from the buffer to the screen |
This means a lot of the calculations needed for computing the outcome (such as the row boundary calculations and combining the mask/background) are done in hiding, whereas the fast copy is only concerned with moving bytes directly between the buffers and screen areas.
In z80 assembler, the fast copy might look something like this:
buffercopy:
ld sp,#addresstable
pop hl ; row 1
ld d,h
ld e,l
res 7,d
ldi
ldi
ldi
pop hl ; row 2
ld d,h
ld e,l
res 7,d
ldi
ldi
ldi
pop hl ; row 3
ld d,h
ld e,l
res 7,d
ldi
ldi
ldi
...
...
...
[16 rows for each sprite]
addresstable:
; Just an example, a sprite in the top left corner
.dw #0XC000,#0XC100,#0XC200,#0XC300,#0XC400,#0XC500,#0XC600,#0XC700
.dw #0XC020,#0XC120,#0XC220,#0XC320,#0XC420,#0XC520,#0XC620,#0XC720
The stack pointer is placed at the beginning of the table, and the addresses are loaded in the HL register using POP HL, which also increments the stack pointer by two. The LDI performs the equivalent of LD (DE),(HL), moving the contents from address at HL to the address at DL, incrementing both DE and HL in the process. For 24-pixel wide sprites, three LDIs are required for one row.
The table could have from-to address pairs, but writing both addresses during buffer drawing proved to be a bit cumbersome. So the "destination" address DE is constructed out of the "from" address HL by altering the high byte. This is a tiny bit slower than POP:ing both from the table, but it also keeps the table shorter for copying purposes. (phase 5)
This address shifting also means the buffer locations cannot be freely chosen. 0XC000 (49152) and the screen address 0X4000 (16384) are in a good relation to each other, as only one bit needs to be changed between them. There are three versions of the above routine, all different depending whether it is about BUFFER->SCREEN, BACKGROUND->BUFFER or BACKGROUND->SCREEN copying.
The lines
Let's get back to where we started: The ZX Spectrum screen order. Despite the fast copying routines, the sprites need to be drawn into the buffer, and at least somewhere during the process, the line order needs to be negotiated. It's no good if the buffer drawing routines, even if hidden, are too slow.
The overall assembler source is a bit too daunting to publish here, as it is largely a Processing-generated bundle of tables and repetitive code, held together with some C. So I'll stick to explaining the overall idea and some of the more interesting points.
Obviously there has to be a table that contains the drawing address for each vertical pixel row. But accessing this table 16 times each time a sprite is drawn would be less than optimal. This can be avoided. But if one wants to avoid conditional jumps (and one wants to avoid them) there has to be a number of variants of the routine, depending on which pixel row the sprite is drawn to.
With eight sprites, any commands added to the pixel drawing order gets repeated not only 8 times, but 128 times or more! So there's a great incentive to remove slow code from the heart of the buffer drawing.
It would be neat to just have a full sprite drawing routine for each vertical pixel row. This would produce 175x16 copies of the sprite row drawing code, which takes far too much memory. The amount can be reduced: there are only 23 ways how a 16-pixel high sprite drawing might unfold. This would produce "only" 23x16 times the row drawing code. It doesn't sound much but still it's more than 20 kilobytes, a bit too much.
What we did was a bit nasty: self modifying code. One pixel row drawing code is repeated only 39 times. Each variant has it's own labeled entry point. When the sprite drawing is invoked, the program jumps into the relevant entry point, depending on the sprite vertical coordinate. (Yet another table) The diagram below describes the whole code portion and an example case:

The example sprite is to be drawn at Y coordinate 20. A vertical address table tells that this row uses the variant 4. The NOP (0x00) instruction at the address of EXIT4: label is overwritten with a RET (0xC9) instruction. HL is loaded with the label ENTRY4: address. JMP (HL) takes the program counter there.
The routine then draws four rows, skips the character boundary, draws another eight rows, skips another character boundary, draws four more rows and exits the drawing routine. The RET is overwritten with a NOP.
The routine then draws four rows, skips the character boundary, draws another eight rows, skips another character boundary, draws four more rows and exits the drawing routine. The RET is overwritten with a NOP.
There have to be rewritten exit points, because only 16 rows are needed, and we want to avoid conditional jumps and wasting registers on counters. So, drawing sprite variant 0 means jumping to the entry label 0, while writing a RET to the EXIT0:. Jumping to entry 4 means writing a RET to the exit point 4 and so on.
The code below describes what happens within the "draw row" portion in the above diagram.
; stack is pointed to the beginning of sprite graphics
; (mask and gfx interleaved)
; de holds the drawing address
; jp(hl) brings the program counter here
; bc holds the beginning of the address table
; de is written to the address table
ld a,e
ld (bc),a
inc bc
ld a,d
ld (bc),a
inc bc
; draw one sprite row to the buffer (3 bytes wide)
; stack handily gives both the mask and the graphic byte
ld a,(de) ;get buffer byte
pop hl ;get mask and gfx
and a,l
or a,h
ld (de),a ;draw to buffer
inc e ;right
ld a,(de) ;get buffer byte
pop hl ;get mask and gfx
and a,l
or a,h
ld (de),a ;draw to buffer
inc e ;right
ld a,(de) ;get buffer byte
pop hl ;get mask and gfx
and a,l
or a,h
ld (de),a ;draw to buffer
EXIT0:
nop ; may be overwritten with ret
After the pixel row, the destination address is adjusted for the next pixel row.
; normal
dec e ;left
dec e ;left
inc d ;down
If the next address crosses the character row, this will be used instead:
; pass the character row boundary
ld a,e
add a,#30
ld e,a
ld a,d
sub a,#7
ld d,a
Or, finally, if the next pixel row is beyond the slice block boundary, this is needed:
; pass the slice block boundary
inc d
ld a,e
add a,#30
ld e,a
That's it for the time being. We think this routine can still be significantly improved. Perhaps the nasty self-writing can be avoided. Perhaps it might be possible to get rid of the un-elegant wipe at the end of the screen. There are some wild ideas brewing, but better not boast about them before they are real...
SDCC Small Device C Compiler. http://sdcc.sourceforge.net/
HEX2BIN. http://hex2bin.sourceforge.net/
FUSE The Free Unix Spectrum Emulator. http://fuse-emulator.sourceforge.net/
Processing. http://www.processing.org/
Smith, Chris. (2010) The ZX Spectrum ULA: How to design a microcomputer. ZX Design and media.
Smith, Derek M. (2004) Sprite Graphics Tutorial. Accessed from www.bobs-stuff.co.uk
Vickers, Steven (1982) ZX Spectrum BASIC programming. Sinclair research.
Zaks, Rodnay (1982) Programming the Z80. Third revised edition. Sybex.
I still believe that a vertical linear 256x256 pixel offscreen buffer would be the fastest option :) Screen refresh needs to be optimized so that there's no need for a separate wipe/draw cycle.
ReplyDeleteAwesome article!
ReplyDeleteThanks very much - this helped me out a load!
Having a good look through this article and very impressed. One point I would make is that you could remove the two DEC E's in the sprite routine by simply storing your sprite imagines in a ZIG ZAG format (hope that makes sense).
ReplyDeleteNice explanation.
ReplyDeleteSelf modifying code is usually seen as "nasty", but was an elegant way to save memory and reuse code back when we only had 16K and 48K to play with.
I was always fascinated by it. It's over 4 years since you posted this and I'm not sure whether you've done any further optimization but I've spotted some areas for improvement.
You said there was 23 ways printing the 16 pixel high sprite could unfold. It's actually 24 (an off-by-one error caused by forgetting that you started at zero).
Rather than 39 copies, you can get away with only 24 copies of your row drawing code if you use a single jump absolute (JP) instruction after the red block (slice) adjustment code back to Entry0. Your EXIT9 to EXIT23 then just move to after the ENTRY0 to ENTRY14 blocks in your ENTRY/EXIT point diagram.
This admittedly adds 10 T-states to any printing that enters via ENTRY9 upwards but it eliminates 15 blocks of drawing and pixel-row adjustment code and the extra block of character-row adjustment code after EXIT16.
You can more than make up for this and save even more space by removing the wasteful NOP spaces (and the associated 4 T-state per row overhead which tops out at 60 T-states per sprite for any Entry point after ENTRY15).
Even the example in your diagram that enters at ENTRY4 has a 16 T-State overhead in NOPs.
You originally created these filler bytes so you could flip them between NOP and RET according to the exit point required. However by rewriting the row-adjustment code slightly we can ensure that the first byte is always a predicatble INC D instruction.
This means we can flip the first byte of the appropriate adjustment code to RET where we need an EXIT and back to INC D after exiting. This means no time or space is wasted on NOP instructions.
So we simply rearrange the Normal (pixel) row adjustment code to become:
INC D
DEC E
DEC E
The Character row adjustment code becomes:
INC D
LD A,D
SUB A,#8
LD D,A
LD A,E
ADD A,#30
LD E,A
The Block (slice) row adjustment code stays as it is, since it already starts with INC D
Although it seems strange to add 4 T-states to increment D only to subtract 8 instead of 7, remember we're trying to make the first byte of each adjustment routine identical.
We can now flip the bytes in the appropriate position between RET and INC D which has the same effect as the original NOP idea but without the speed or program space overhead.
Thank you for the insightful comments and pointing out the mistake :) Getting rid of the NOPs was not something I ever thought of.
DeleteIf I get back to this topic I'll probably rewrite the whole thing in a proper macro-assembler. The old source is not easy to tinker with after all these years. The routine that ultimately copies the sprites to the screen is likely nearly as fast as it can be, and if I recall correctly it could paste 12 sprites before the beam hits the visible screen area. The rest of the routine is not up to it though, but managing 10 sprites within a frame might be a possibility with better optimizations.
If it was possible to trick the interrupt to start from the bottom of the screen, just before the vblank area, it would make things easier.
Love the way programming happened back then. With such limited memory and processor ticks per frame it really brought the creativity out of good programmers. Personally I think SMC was a perfectly legitimate method of reusing code and saving space. It could however get ludicrously convoluted and complicated.
ReplyDeleteChanging the address/value part of a nearby opcode in 6502 at least was probably done quite often, well, at least I tend to use it. Changing opcodes itself was probably frowned upon a bit.
DeleteIs the source code available?
ReplyDeleteMight be cool to know that this piece of code: " The BASIC program below identifies the slice block and character rows for a given vertical pixel coordinate, and draws the "sprite" accordingly." was used on a screen texture of the game Beyond_a_Steel_Sky! It's in the scene with (the fake) Leet in a background monitor: https://imgur.com/a/zIM16MC
ReplyDeleteWhat the...? :) The graphic data is different. Tried it, it displays maybe some kind of critter.
DeleteThis is a really cool tutorial but way more advanced than my current ZX Spectrum/Z80 skills ro replicate. Would you be ok with providing the source code?
ReplyDeleteHi, thanks for the comment. Currently it's difficult to even find the source pieces anymore. It is a mess of c and assembler. Also, much of the code is just repetitive elements which are automatically generated anyway, so it's not very readable.
DeleteAlso, this was more about proving a point and not a genuinely useful routine. It takes way too much memory and processor time.
Just spotted some of this code on Leet's monitor in Beyond a Steel Sky!
ReplyDeleteVery Nice!
ReplyDelete